
|
Summary Using natural language processing, a system of using artificial intelligence to understand text, the author constructs a predictor based on a simple, constrained, description of the solar system on the start dates of various world historical events (n=7819). This predictor is then statistically shown to be effective at characterizing similar events of the past. An online offering of this predictor for use of characterizing the future accompanies this write-up. Introduction Understandably, the future is a subject of shared fascination. Future history is a term of ripe heritage. Typically, it is used to describe works of science fiction. What if future historical events could be predicted computationally, even if hazily? This paper shows that the simple solar system astronomy of historical event start dates can map onto similar major world events of the past as numerically measured by textual analysis of one-sentence descriptors. By looking at the astronomy that accompanies future dates, those textual characterizations can easily be employed to see astronomy mappings onto historical events. Methods and Materials The project makes heavy use of the Mathematica system of knowledge representation, computation, and analysis. Characterization of Historic Events Dataset The first step is to seek the historical events. What counts as a true historical event? What counts as the start date? How does one even characterize a world event given differing cultural perceptions? For ancient events, how confident can one be for either the start date or the description? These are all excellent questions that the author largely side stepped by employing Mathematica’s “Historical Events” feature. There were 7819 such events available thereby with start dates and one-line descriptions included. The sources from Mathematica for this historical event dataset are numerous. They can be found through this mechanism. The following is a set of descriptors for 400 or so example historic events out of the 7819.  A word cloud for the descriptors of the full set of 7819 follows. Any date numbers and parentheses were removed before computing the word cloud.  The distribution of locations of the historic events is as follows.  A timeline of the start dates for the 7819 historic events is highly compressed within the last few millennia. All but seven were in the last 6000 years. 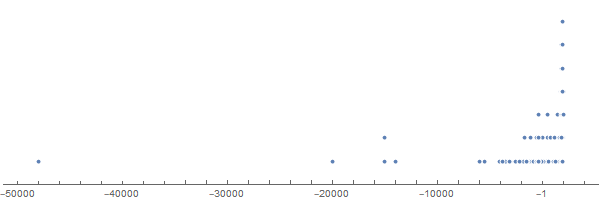 Thus, one can be sure that the historic events are not evenly distributed culturally, geographically, or over time. Nonetheless, for the historical events that are in the dataset, can a mathematical model be constructed that gives similar numbers for events that are similar in their one-line text descriptions? That is a task for text analysis. As of this writing, the author believes that Google’s BERT is the best available resource for such a task. To translate the one sentence descriptors (sans dates and parentheses) into feature space, the BERT encoder with a pooling layer was used. For each historical event, the 768-long vector of numbers that resulted from the pooling layer was reduced to a single number through collective dimension reduction. Events that are similar textually, e.g. earthquakes or assassinations, are close by in number and hence in the feature space. The following is a 2-D plot of that feature space. 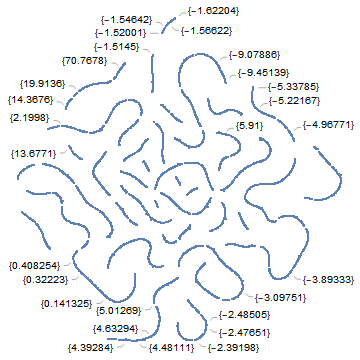 The simple geocentric astronomy of the start date was mapped onto this unique feature space number for each event. The question then becomes: can the astronomy of an event’s start date describe the feature space number and by extension, the textual description of the event? A randomization created a training set of 6000 events, a validation set of the next 1000 events, and a test set of the following 819 events. The simple astronomy considered here are right ascensions (i.e. Tropical degrees) of Sun, Moon, Mercury, Venus, Mars, Jupiter, Saturn, Uranus, Neptune, and Pluto. To be sure, more solar system planetary details (such as retrogressions) could have been included, as well as those of nodes, asteroids, etc. The focus here on historical events though asks that we consider the more slow-moving solar system entities, at least as is understood through astrology discourse. A method using gradient-boosted trees was automatically selected for predicting the BERT encoder’s value for a text description based only on the set of astronomy placements for the start of an event. Results A 2.4 percent reduction in standard deviation from baseline was achieved in the test set with some linearity emerging of actual value plotted against predicted value. (R-squared is 0.0475.) 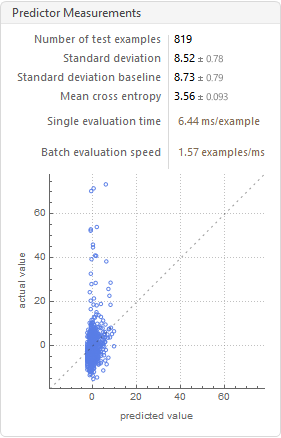 Moreover, when the full set of 7819 historical events were evaluated at once, the internal testing showed a lower entropy (loss).  It is this latter predictor function, based on the full events dataset, that is offered for use at AyurAstro.com: www.ayurastro.com/history-predictor.html#/
Conclusion To be sure, more astronomical features can be tested. As well, a more inclusive dataset could be used. This relatively short study nonetheless offers a demonstration of the use of astronomical features in predicting context and vocabulary for describing historical events whether in the past, present, or future.
1 Comment
3/29/2020 04:41:22 pm
Time is so not linear! What an incredible model and study. Disasters are so very documented, I wonder what this would look like for miracles or enlightenment or the birth of avatars... Your comment will be posted after it is approved.
Leave a Reply. |
ARTICLESAuthorRenay Oshop - teacher, searcher, researcher, immerser, rejoicer, enjoying the interstices between Twitter, Facebook, and journals. Categories
All
Archives
September 2023
|
 RSS Feed
RSS Feed
© 2008–2024 Renay Oshop AyurAstro®